= B-Tree 구조로 저장된다 ( select 효율을 돕힌다 )
B -Tree 구조란?
= 탐색 성능을 높히기 위해 균형있는 높이를 유지하는 트리구조
편향 트리를 사용하면 모든 키값을 조회하여 찾기에 시간이 오래걸리지만, 균형 트리를 사용하면 데이터를 삭제 하거나 삽입해도 균형을 최대한 유지하며, 순차 접근이 가능하게 한다
노드가 최대 몇개의 데이터를 가지는지가 중요하다
노드 최대 : M개 → 최대 자식 노드 : M+1개
* 노드 : 하나의 자료 구조에 포함된 정보
root node : 트리 구조의 가장 높은 지점
intermediate node : 트리 구조의 중간 지점
leaf node : 트로 구조의 가장 거리가 먼 지점
B트리 탐색
= 루트 노드 부터 아래 자식 노드로 이동하면서 찾는다
B트리 삽입
= 노드 분열로 삽입시킴, 오름차순으로 데이터가 들어온다
1. 노드가 비어있을 때

빈 곳으로 데이터가 들어간다
2. 노드의 공간이 없을 때

데이터 중 중간값인 것을 골라 부모 노드로 올리고, 나머지 값들은 2개로 분열시킨다
B트리 삭제
1. 리프 노드에서 삭제
- 형제 노드에서 빌려오기

부모 노드에서 값 하나를 내준다
2. 중간 노드에서 삭제
- 자식 노드 병합

남은 자식노드를 병합 시킨다
참고) [자료구조] B 트리 :: 개발자로 홀로 서기 (tistory.com)
[자료구조] B 트리
안녕하세요. 오늘은 B 트리 에 대해 포스팅 합니다. B 트리 는 이진 탐색 트리의 일종으로 탐색 성능을 높이기 위해 균형있게 높이를 유지하는 균형 트리 입니다. 균형 이진 탐색 트리는 대표적으
mommoo.tistory.com
인덱스에 적용한 B-Tree를 보면
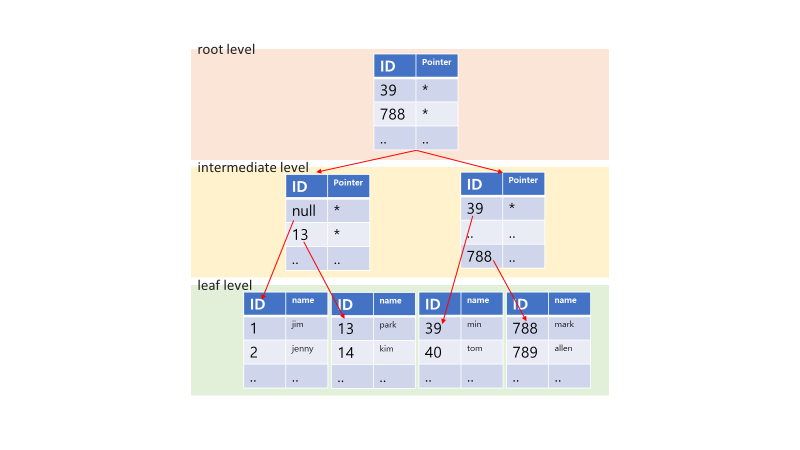
root, intermediate에는 pointer, ID 값만 존재하고 leaf에는 ID와 데이터 값이 존재한다
인덱스 종류
클러스터 형 : 테이블 자체를 인덱스로 만드는 형태

Birth라는 데이터를 키로 뒀을 때 Birth외 데이터들은 정렬되지 않는다
- PRIMARY KEY 를 설정하면 자동 생성된다
- 테이블 하나씩에만 적용할 수 있다
- 물리적으로 행을 정렬한다
생성 방법) CREATE CLUSTERED INDEX '인덱스 이름' ON '테이블 이름' ('컬럼 이름')
비 클러스터 형 : 테이블과는 독립적으로 생성되며 정의된 키값과 함께 테이블의 행 위치 주소를 저장해 관리한다

RID : 각행을 구별하는 식별자로 파일 번호 + 페이지 번호 + 슬롯 번호로 혼합되어 있다
- UNIQUE 을 설정하면 자동 생성된다
- 테이블 여러개에 적용할 수 있다
- 물리적으로 행을 정렬하지 않는다
생성 방법) CREATE NONCLUSTERED INDEX '인덱스 이름' ON '테이블 이름' ('컬럼 이름')
+ 참고)
primary key : 데이터 유일성 보장, NULL값 허용 X
unique key : 데이터 유일성 보장, NULL값 허용 O
클러스터 종류, key 종류 확인하는 법 : SP_HELPINDEX '테이블이름'
참고) MSSQL 테이블 작성 인덱스 생성 하기 (tistory.com)
MSSQL 테이블 작성 인덱스 생성 하기
SQL Server 테이블에 인덱스(INDEX)를 추가하는 방법을 보겠습니다. 테이블을 만드는 CREATE에 추가해 테이블 생성할 때 인덱스를 같이 설정하는 방법과 이미 만들어진 테이블에 인덱스를 추가하는
ponyozzang.tistory.com
인덱스 스캔 방식
Scan : 테이블 전체 혹은 인덱스 전체를 읽는다 ( 수평적 탐색 )

- Table Scan : 테이블 전체를 조회하는 방식
select * from [Table] --PRIMARY KEY 키가 없을 때- 클러스터 Index Scan : 인덱스 키로 지정된 열을 탐색하는 방식, But 키가 인덱스가 아니면 모든 데이터를 읽어야됨
select * from [Table] --PRIMARY KEY가 존재할 때
select * from [Table] where name = '이름' --PRIMARY KEY가 존재하나 name은 PK키가 아님- 비 클러스터 Index Scan : 요구되는 열들이 다 포함되 있지만, 탐색 조건으로 사용될 수 없을 때 모든 행을 조회
Seek : 인덱스를 통해 조건에 해당하는 특정 범위만 읽는다 ( 수직적 탐색 )

- 클러스터 Index Seek : 클러스터형 인덱스 키값을 통해 조건을 탐색해 만족하는 범위만 읽는 방식, 키가 인덱스가 아 니여도 OK
select * from [Table] where GROUP_CODE='Code' --GROUP_CODE가 PRIMARY KEY 일 때- 비 클러스터 Index Seek : 키로 지정한 열이 탐색 조건으로 사용되는 경우 특정 범위만 탐색하여 행을 비교하며 조건과 일치하지 않으면 탐색을 종료한다
참고) 쿼리문을 실행할 때 F5가 아닌 Ctrl + L 실행 시 어떤 방식으로 검색되는지 확인 할 수 있음
포괄열 있는 인덱스
비 클러스터는 데이터 테이블과 인덱스 테이블이 따로있다고 했는데
이는 RID LOOK 실행에서 많은 조인을 불러오기에 성능이 안좋아진다
create nonclustered index 인덱스명 테이블명(인덱스 키) include(포괄열)포괄열에 데이터를 포함시키지 않았을 때
create index NID on employee(Birth)
select name, Birth from employee where Birth ='901101'
데이터를 가져올 때마다 join을 걸어 데이터가 100만건이면 100만번 join해야됨
조인을 불러오는 걸 막기 위해 include에 select 되는 데이터를 포함시켜야된다
포괄열에 데이터를 포함시켰을 때
create index NID on employee(Birth) include(name)
select name, Birth from employee where Birth ='901101'
이미 테이블에 birth데이터와 name 데이터가 있으므로 join시킬 필요가 없다
인덱스 조각화
= 정렬된 인덱스 페이지의 논리적 순서와 물리적 순서가 일치하지 않는 것
Be-Tree로 정렬된 테이블에 데이터가 삽입될 때 생기고 데이터를 다른 테이블로 이관시킬 때도 페이지가 늘어난다
데이터가 삽입되고 안정적인 모양을 유지하기 위해 빈 공간이 남을 수 있는데 이는 페이지 사용 효율성을 저하시킴
해결 방법) 인덱스를 다시 구성한다 : 물리적으로 재 정렬하여 새로운 페이지를 할당받는다
alter index [idex키 이름] on [Table이름] REBUILD